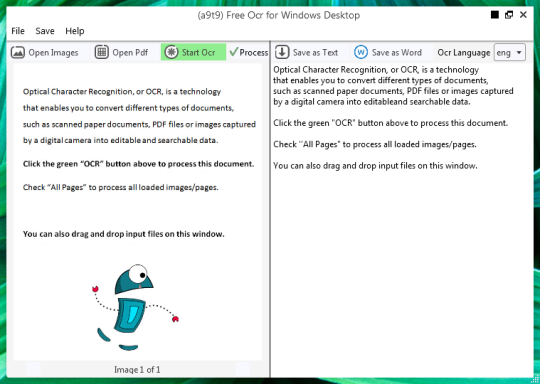
Δωρεάν λογισμικό OCR για να εξαγάγετε κείμενο από αρχεία εικόνων και αντικειμένων PDF. Μια γραφική διεπαφή χρήστη (GUI) για τον κινητήρα Tesseract OCR.
Η εφαρμογή είναι απλό στην εγκατάσταση και, το πιο σημαντικό, ελεύθερη να χρησιμοποιήσει, ανοιχτού κώδικα και 100% spyware και adware δωρεάν.
Μπορείτε να ανοίξετε ένα αρχείο εικόνας ή PDF. Το περιεχόμενο του αρχείου πηγαίου κώδικα θα εμφανιστεί στο αριστερό παράθυρο. Αν το έγγραφό σας ως κάτι περισσότερο από μια σελίδα, ή αν ανοίξει πολυσέλιδων εγγράφων, χρησιμοποιήστε τα βέλη στο κάτω μέρος για εναλλαγή μεταξύ τους,
Μπορείτε να ξεκινήσετε το OCR, κάνοντας κλικ στο πράσινο κουμπί OCR, και θα δείτε το αποτέλεσμα στο δεύτερο δεξί παράθυρο. Κείμενο εξόδου μπορεί να αποθηκευτεί ως αρχείο κειμένου ή ένα έγγραφο του Word.
Δυστυχώς, η ποιότητα μετατροπής δεν είναι τόσο μεγάλη. Πίσω από τη σκηνή που χρησιμοποιεί το Tesseract open-source μηχανή OCR. Η ποιότητα διαφέρει από γλώσσα σε γλώσσα -. Ώστε να προχωρήσει και δοκιμής, εάν είναι επαρκής για τις ανάγκες σας
Για τους προγραμματιστές λογισμικού και geeks: The Δωρεάν OCR για το εργαλείο των Windows Desktop είναι ουσιαστικά μια γραφική διεπαφή χρήστη front-end (GUI) για τον κινητήρα Tesseract OCR. Η πλήρης πηγαίου κώδικα είναι διαθέσιμη (άδεια GPL).
Η μηχανή OCR του λογισμικού υποστηρίζει την ακόλουθη γλώσσα OCR: Αγγλικά, Γαλλικά, Ιταλικά, Γερμανικά, Ισπανικά, Πορτογαλικά Βραζιλίας και Ολλανδικά. Ξεκινώντας με την έκδοση 3 μπορεί να αναγνωρίσει Αραβικά, Βουλγαρικά, Καταλανικά, Κινέζικα (απλοποιημένα και παραδοσιακά), Κροατικά, Τσεχικά, Δανικά, Ολλανδικά, Αγγλικά, Γερμανικά (πρότυπο και Fraktur σενάριο), Ελληνικά, Φινλανδικά, Γαλλικά, Εβραϊκά, Χίντι, Ουγγρικά, Ινδονησιακά, Ιταλικά, Ιαπωνικά, Κορεατικά, λετονικά, λιθουανικά, νορβηγικά, πολωνικά, πορτογαλικά, ρουμανικά, ρωσικά, σερβικά, σλοβακικά (πρότυπο και Fraktur σενάριο), Σλοβενικά, Ισπανικά, Σουηδικά, Ταγκαλόγκ, Ταμίλ, Ταϊλανδικά, Τουρκικά, Ουκρανικά και Βιετναμέζικα.
Τα σχόλια δεν βρέθηκε